有偿问答
面经分享
技术探讨
资料领取
登录
面试官:哈希表都不知道,你是怎么看懂HashMap的?*
社长
1年前
⋅ 368 阅读
HashMap 是 Java 面试中的必问考点之一,网上关于 HashMap 实现原理的文章数不胜数。但是在翻阅了大部分 HashMap 相关的文章之后,发现大多数文章都是对 HashMap 源码的分析,丝毫没有提到哈希表的概念。这就导致了很多人只记住了 HashMap 的原理,却不知哈希表为何物的奇特现象。很多情况下,面试官可能并不会直接问 HashMap 是如何实现的,而是抛出一个质问三连:  > 本文原文地址 [https://juejin.cn/post/6876105622274703368](https://juejin.cn/post/6876105622274703368) 搞错了,重来!什么是哈希表?什么是哈希冲突?如何处理哈希冲突?  对于不了解哈希表的同学,这三个问题确实触及到了知识盲区。为了避免这种尴尬,接下来就一起来学习一下哈希表吧。 一、什么是哈希表? --------- 在回答这个问题之前我们先来思考一个问题:**如何在一个无序的线性表中查找一个数据元素?** 注意,这是一个无序的线性表,也就是说要查找的这个元素在线性表中的位置是随机的。对于这样的情况,想要找到这个元素就必须对这个线性表进行遍历,然后与要查找的这个元素进行比较。这就意味着查找这个元素的时间复杂度为 o(n)。对于 o(n) 的时间复杂度,在查找海量数据的时候也是一个非常消耗性能的操作。那么有没有一种数据结构,这个数据结构中的元素与它所在的位置存在一个对应关系,这样的话我们就可以通过这个元素直接找到它所在的位置,而此时查找这个元素的时间复杂度就变成了 o(1), 可以大大节省程序的查找效率。当然,这种数据结构是存在的,它就是我们今天要讲的**哈希表**。 我们先来看一下哈希表的定义: > **哈希表**又叫**散列表**,是一种根据设定的映射函数 f(key)将一组关键字映射到一个有限且连续的地址区间上,并以关键字在地址区间中的 “像” 作为元素在表中的存储位置的一种数据结构。这个映射过程称为**哈希造表**或者**散列**,这个映射函数 f(key) 即为**哈希函数**也叫**散列函数**,通过哈希函数得到的存储位置称为**哈希地址**或**散列地址** 定义总是这么的拗口且难以理解。简单来说,哈希表就是通过一个映射函数 f(key) 将一组数据散列存储在数组中的一种数据结构。在这哈希表中,每一个元素的 key 和它的存储位置都存在一个 f(key) 的映射关系,我们可以通过 f(key) 快速的查找到这个元素在表中的位置。 举个例子,有一组数据:[19,24,6,33,51,15],我们用散列存储的方式将其存储在一个长度为 11 的数组中。采用**除留取余法**,将这组数据分别模上数组的长度(即 f(key)=key % 11),以余数作为该元素在数组中的存储的位置。则会得到一个如下图所示的哈希表: 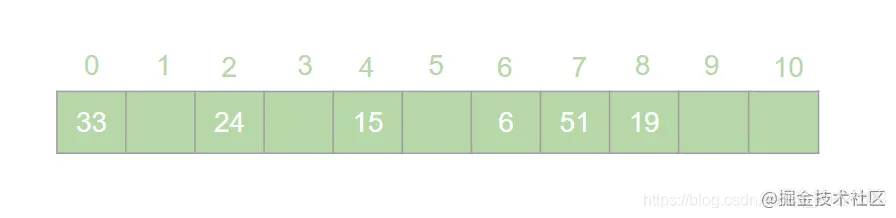 此时,如果我们想从这个表中找到值为 15 的元素,只需要将 15 模上 11 即可得到 15 在数组中的存储位置。可见哈希表对于查找元素的效率是非常高的。 二、什么是哈希冲突 --------- 上一节中我们举了一个很简单的例子来解释什么是哈希表,例子中的这组数据只有 6 个元素。假如我们向这组数据中再插入一些元素,插入后的数据为:[19,24,6,33,51,15,25,72],新元素 25 模 11 后得到 3,存储到 3 的位置没有问题。而接下来我们对 72 模 11 之后得到了 6,而此时在数组中 6 的位置已经被其他元素给占据了。“72“只能很无奈的表示我放哪呢? 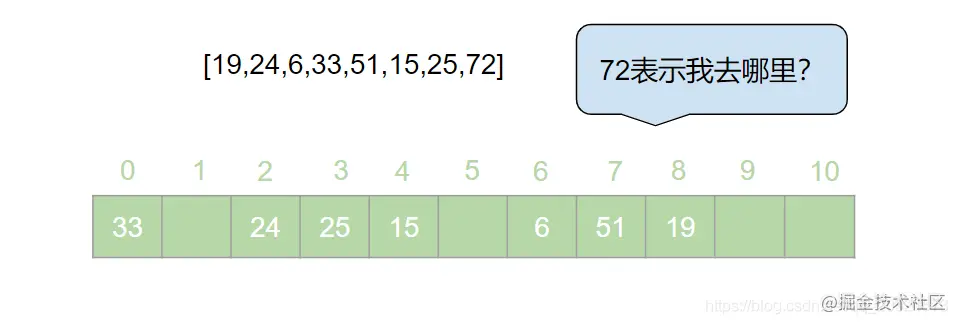 对于上述情况我们将其称之为哈希冲突。哈希冲突比较官方的定义为: > 对于不同的关键字,可能得到同一个哈希地址,即 key1≠key2, 而 f(key1)=f(key2),对于这种现象我们称之为**哈希冲突**,也叫**哈希碰撞** 一般情况下,哈希冲突只能尽可能的减少,但不可能完全避免。因为哈希函数是从关键字集合到地址集合的映射,通常来说关键字集合比较大,它的元素理论上包括所有可能的关键字,而地址集合的元素仅为哈希表中的地址值。这就导致了哈希冲突的必然性。 ### 1. 如何减少哈希冲突? 尽管哈希冲突不可避免,但是我们也要尽可能的减少哈希冲突的出现。一个好的哈希函数可以有效的减少哈希冲突的出现。那什么样的哈希函数才是一个好的哈希函数呢?通常来说,一个好的哈希函数对于关键字集合中的任意一个关键字,经过这个函数映射到地址集合中任何一个集合的概率是相等的。 常用的构造哈希函数的方法有以下几种: **(1)除留取余法** 这个方法我们在上边已经有接触过了。取关键字被某个不大于哈希表长 m 的数 p 除后所得余数为哈希地址。即:f(key)=key % p, p≤m; **(2)直接定址法** 直接定址法是指取关键字或关键字的某个线性函数值为哈希地址。即: f(key)=key 或者 f(key)=a*key+b、 **(3)数字分析法** 假设关键字是以为基的数(如以 10 为基的十进制数),并且哈希表中可能出现的关键字都是事先知道的,则可以选取关键字的若干位数组成哈希表。 当然,除了上边列举的几种方法,还有很多种选取哈希函数的方法,就不一一列举了。我们只要知道,选取合适的哈希函数可以有效减少哈希冲突即可。 ### 2. 如何处理哈希冲突? 虽然我们可以通过选取好的哈希函数来减少哈希冲突,但是哈希冲突终究是避免不了的。那么,碰到哈希冲突应该怎么处理呢?接下来我们来介绍几种处理哈希冲突的方法。 **(1)开放定址法** 开放定址法是指当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。 我们以本节开头的例子来讲解开放定址法是如何处理冲突的。72 模 11 后得到 6,而此时 6 的位置已经被其他元素占用了,那么将 6 加 1 得到 7, 此时发现 7 的位置也被占用了,那就再加 1 得到下一个地址为 8,而此时 8 仍然被占用,再接着加 1 得到 9,此时 9 处为空,则将 72 存入其中,即得到如下哈希表: 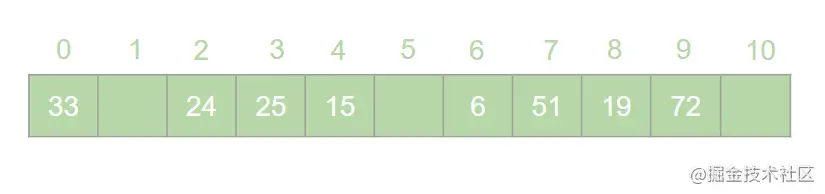 像上边的这种探测方法称为**线性探测再散列**。当然除了线性探测再散列之外还有二次探测再散列,探测地址的方式为原哈希地址加上 d (d= ±12、±22、±32......±m2),经过二次探测再散列后会得到求得 72 的哈希地址为 5,存储如下图所示: 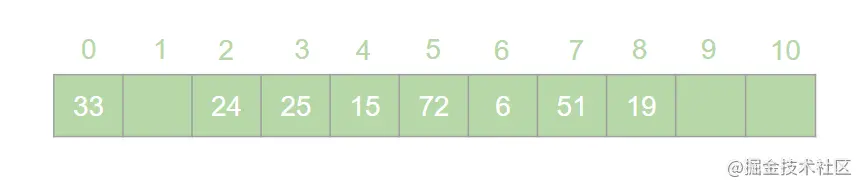 **(2)再哈希法** 再哈希法即选取若干个不同的哈希函数,在产生哈希冲突的时候计算另一个哈希函数,直到不再发生冲突为止。 **(3)建立公共溢出区** 专门维护一个溢出表,当发生哈希冲突时,将值填入溢出表。 **(4)链地址法** 链地址法是指在碰到哈希冲突的时候,将冲突的元素以链表的形式进行存储。也就是凡是哈希地址为 **i** 的元素都插入到同一个链表中,元素插入的位置可以是表头(**头插法**),也可以是表尾(**尾插法**)。我们以仍然以 [19,24,6,33,51,15,25,72] 这一组数据为例,用链地址法来进行哈希冲突的处理,得到如下图所示的哈希表: 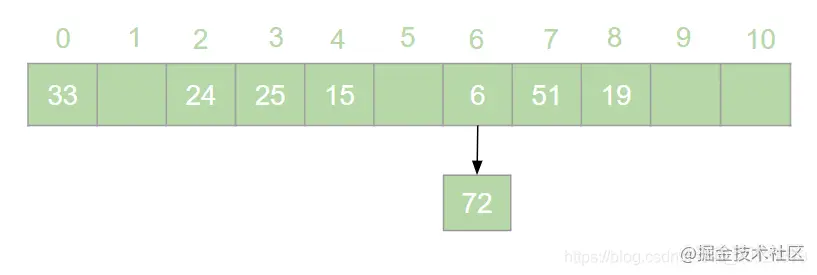 我们可以向这组数据中再添加一些元素,得到一组新的数据 [19,24,6,33,51,15,25,72,37,17,4,55,83]。使用链地址法得到如下哈希表: 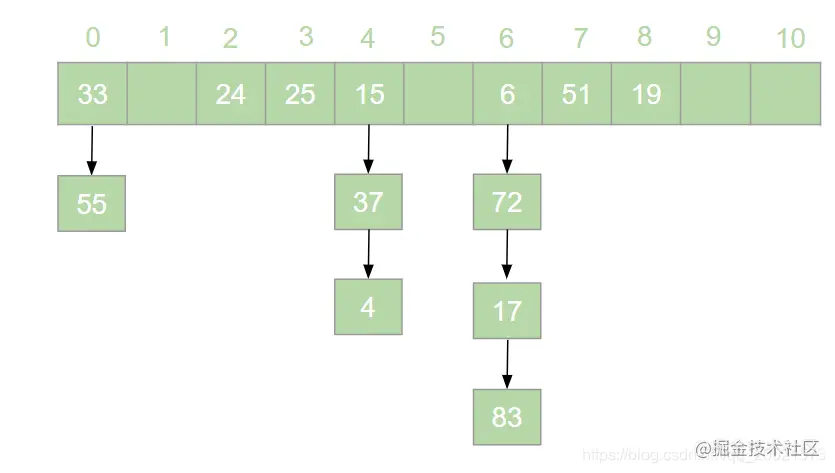 三、链地址法的弊端与优化 ------------ 上一节中我们讲解了几种常用的处理哈希冲突的方法。其中比较常用的是链地址法,比如 HashMap 就是基于链地址法的哈希表结构。虽然链地址法是一种很好的处理哈希冲突的方法,但是在一些极端情况下链地址法也会出现问题。举个例子,我们现在有这样一组数据:[48,15,26,4,70,82,59]。我们将这组数据仍然散列存储到长度为 11 的数组中,此时则得到了如下的结果: 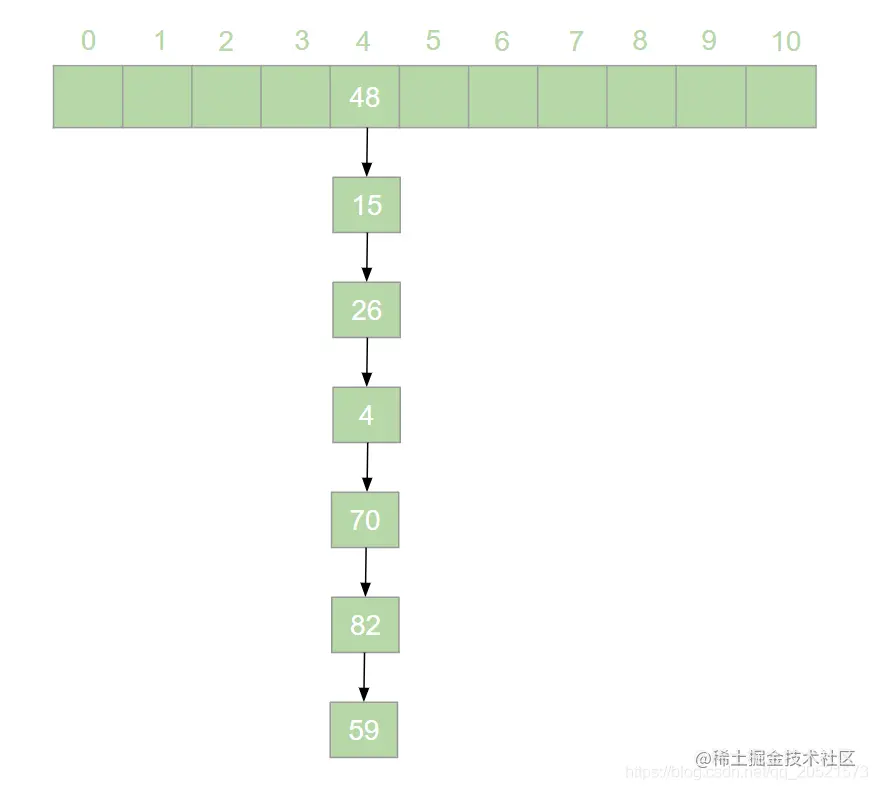 可以发现,此时的哈希表俨然已经退化成了一个链表,当我们在这样的数据结构中去查找某个元素的话,时间复杂度又变回了 o(n)。这显然不符合我们的预期。因此,当哈希表中的链表过长时就需要我们对其进行优化。我们知道,二叉查找树的查询效率是远远高于链表的。因此,当哈希表中的链表过长时我们就可以把这个链表变成一棵红黑树。上面的一组数据优化后可得到如下结果: 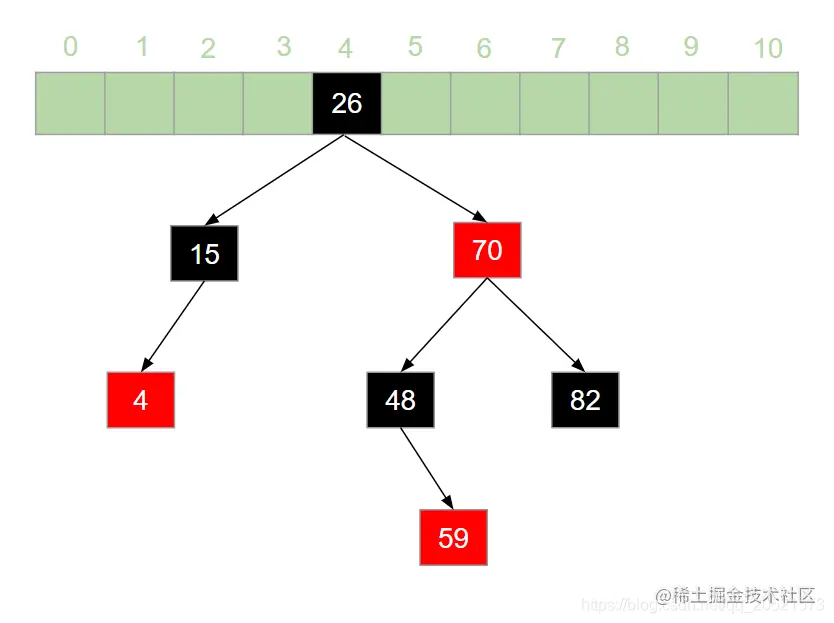 红黑树是一个可以自平衡的二叉查找树。它的查询的时间复杂度为 o(lgn)。通过这样的优化可以提高哈希表的查询效率。 四、哈希表的扩容与 Rehash ---------------- 在哈希表长度不变的情况下,随着哈希表中插入的元素越来越多,发生哈希冲突的概率会越来越大,相应的查找的效率就会越来越低。这意味着影响哈希表性能的因素除了哈希函数与处理冲突的方法之外,还与哈希表的**装填因子**大小有关。 > 我们将哈希表中元素数与哈希表长度的比值称为**装填因子**。装填因子 **α= 哈希表长度哈希表中元素数** 很显然,**α**的值越小哈希冲突的概率越小,查找时的效率也就越高。而减小**α**的值就意味着降低了哈希表的使用率。显然这是一个矛盾的关系,不可能有完美解。为了兼顾彼此,装填因子的最大值一般选在 0.65~0.9 之间。比如 HashMap 中就将装填因子定为 0.75。一旦 HashMap 的装填因子大于 0.75 的时候,为了减少哈希冲突,就需要对哈希表进行**扩容**操作。比如我们可以将哈希表的长度扩大到原来的 2 倍。 这里我们应该知道,扩容并不是在原数组基础上扩大容量,而是需要申请一个长度为原来 2 倍的新数组。因此,扩容之后就需要将原来的数据从旧数组中重新散列存放到扩容后的新数组。这个过程我们称之为 **Rehash**。 接下来我们仍然以 [19,24,6,33,51,15,25,72,37,17,4,55,83] 这组数据为例来演示哈希表扩容与 Rehash 的过程。假设哈希表的初始长度为 11,装载因子的最大值定位 0.75,扩容前的数据插入如下图所示: 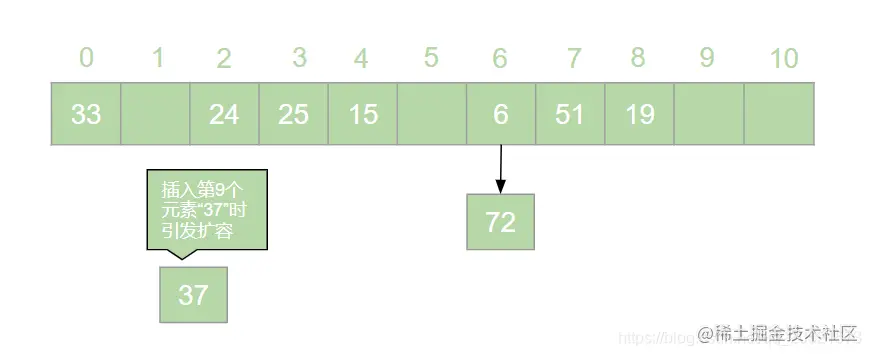 当我们插入第 9 个元素的时候发现此时的装填因子已经大于了 0.75,因此触发了扩容操作。为了方便画图,这里将数组长度扩展到了 18。扩容后将 [19,24,6,33,51,15,25,72,37,17,4,55,83] 这组数据重新散列,会得到如下图所示的结果: 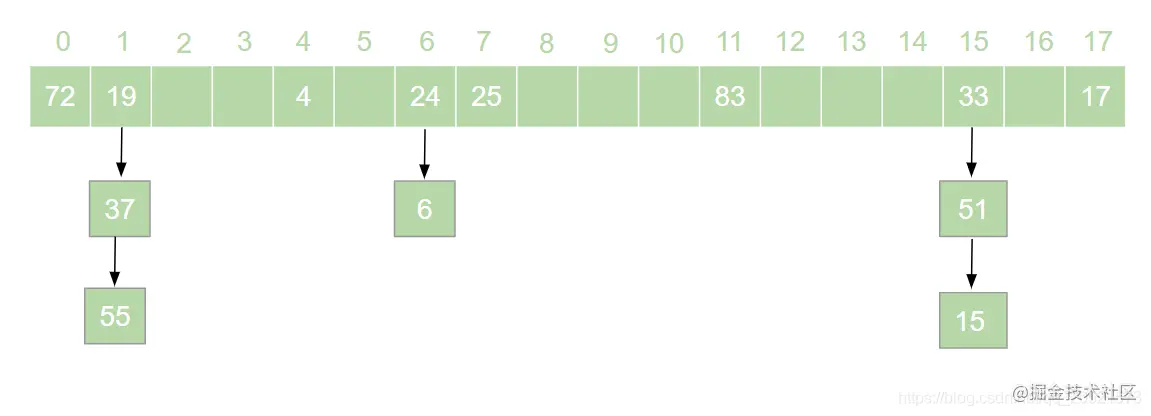 可以看到扩容前后元素存储位置大相径庭。Rehash 的操作将会重新散列扩容前已经存储的数据,这一操作涉及大量的元素移动,是一个非常消耗性能的操作。因此,在开发中我们应该尽量避免 Rehash 的出现。比如,可以预估元素的个数,事先指定哈希表的长度,这样可以有效减少 Rehash。 五、总结 ---- 哈希表是数据结构中非常重要的一个知识点,本篇文章详细的讲解了哈希表的相关概念,让大家对哈希表有了一个清晰的认识。哈希表弥补了线性表或者树的查找效率低的问题,通过哈希表在理想的情况下可以将查找某个元素的时间复杂度降低到 o(1), 但是由于哈希冲突的存在,哈希表的查找效率很难达到理想的效果。另外,哈希表的扩容与 Rehash 的操作对哈希表存储时的性能也有很大的影响。由此可见使用哈希表存储数据也并非一个完美的方案。但是,对于查找性能要求高的情况下哈希表的数据结构还是我们的不二选择。 最后了解了哈希表对于理解 HashMap 会有莫大的帮助。毕竟 HashMap 本身就是基于哈希表实现的。
阅读全部
全部评论:
0
条
我有话说:
@
发送
-- 目录 --
关注官方公众号:
Java问答社
接收最新有赏问答推送!
最新发布
1.
SpringBoot 接口数据加解密技巧,so easy!
2.
一个依赖搞定 Spring Boot 反爬虫,防止接口盗刷!
3.
Java8 Stream 极大简化了代码,它是如何实现的?
4.
马上大四了,秋招还是春招好?先找工作还是找实习?
5.
万字详解 Linux 常用指令(值得收藏)
6.
4年工作经验,多线程间的5种通信方式都说不出来,你敢信?
最新评论
部署文档没有了,您能提供下吗
部署文档没有了,能提供下吗
我测你的🐎
源码从哪里获取请问
想学
那篇石墨文档 没有权限查看哇